Multi-Modal Federated Learning on Non-IID Data
Existing work in federated learning focused on addressing uni-modal tasks, where training generally embraces one modality, such as images or texts. As a result, the global model is uni-modal, containing a modality-specific neural network structure, using samples from a specific modality as its input for training. It is intriguing to explore how federated learning can be extended to the realm of multi-modal tasks effectively, as models are trained with datasets from multiple modalities, such as images and texts. Though several existing studies proposed to train multi-modal models with federated learning, the specific challenges imposed by non-IID data distributions in the context of multi-model federated learning, referred to as multi-modal FL, have not been explored.
When non-IID data in federated learning is referenced, this typically refers to differences between local data distributions for different clients. The most common one is the distribution-based label non-IID data in which class distribution among clients follows the Dirichlet distribution.
The original objective of this project is to foray into uncharted territory by focusing on the effects of non-IID data distributions in multi-modal FL. Intuitively, as more information is available from complementary modalities, multi-modal FL should outperform the corresponding uni-modal FL. However, we make the counter-intuitive observation from our experimental results that multi-modal FL not only leads to more communication rounds needed to reach convergence, but also lags far behind conventional uni-modal FL with respect to the accuracy of trained models.
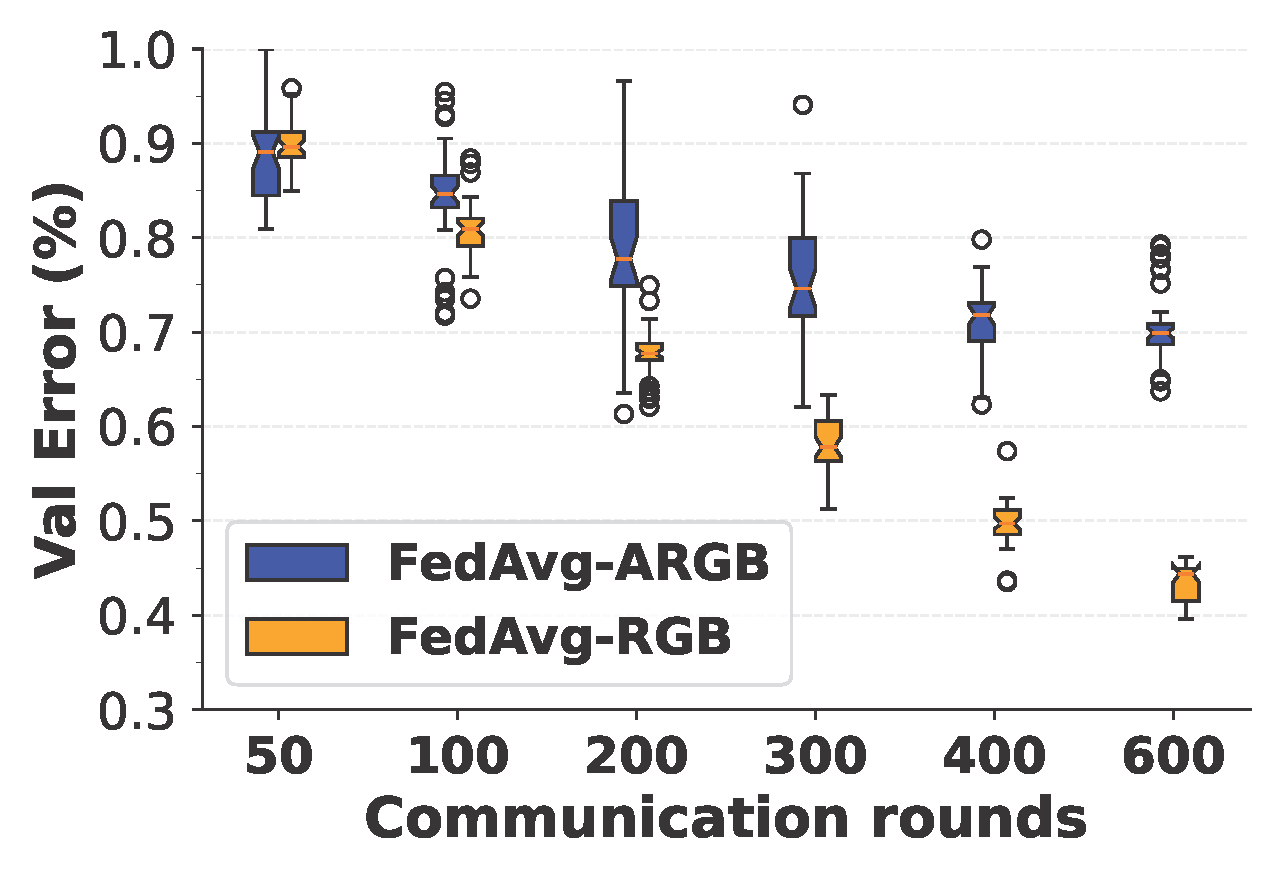
Figure. A performance comparison between the Federated Averaging (FedAvg) algorithm with uni-modal FL, called FedAvg-RGB, and multi-modal FL, called FedAvg-ARGB, performed on the Kinetics dataset. With FedAvg-RGB, images are used as the sole input for training the global model; while with FedAvg-ARGB, both images and audio are used as input for training. Each client computes the validation accuracy by evaluating the updated local model on the local validation dataset. Boxplots are used to show the divergence among local models at participating clients.
We support this claim by training global models for the action recognition task using distribution-based label non-IID data, where the class distribution among clients follows the Dirichlet distribution (with a concentration parameter of 0.5). The classical FL algorithm, named Federated Averaging (FedAvg), is applied to train the uni-modal and multi-modal global models, abbreviated as FedAvg-RGB and FedAvg-ARGB, respectively. Specifically, two empirical observations can be drawn from the figure above. First, the overall validation accuracy of FedAvg-RGB is consistently higher than that of FedAvg-ARGB during the training process. As the number of communication rounds increases, the performance of the multi-modal model lags behind that of the uni-modal model by an increasing margin. Second, compared with FedAvg-RGB, FedAvg-ARGB shows a higher degree of divergence across participating clients with respect to the validation accuracy over their local models. This, in general, causes a lower convergence speed and a lower final accuracy after convergence is achieved.
To address this challenge, we reveal how non-IID multi-modal data affects the federated training process by presenting a thorough theoretical analysis. Our results have shown that multi-modal FL’s lower performance can be attributed to weight divergence, which quantifies the difference of weights updated based on non-IID multi-modal data and centralized data. Specifically, due to the complexity of non-IID multi-modal data, both the local data distribution across clients and the distribution between modalities can be extremely heterogeneous. As a result, multi-modal models are often prone to overfitting as they are trained on unbalanced and small-size local datasets. To make matters worse, overfitting and inconsistent generalization rates appear in the modality subnetworks and the local models simultaneously. With uni-modal FL, existing mechanisms have been proposed to address the problems of overfitting and heterogeneity among clients, such as local adaptation and weighted global aggregation. However, our experiments show that these mechanisms were not able to provide an effective solution in the context of multi-modal FL.
Built upon these theoretical insights, the crux of this work is the design of a new mechanism, referred to as hierarchical gradient blending (HGB), that adaptively computes an optimal blending of modalities and reweighs updates from the clients according to their overfitting and generalization behaviour. Intuitively, HGB corresponds to an optimization problem with overfitting-to-generalization rate minimization as the objective function.
$$\min_{\left\{z_m\right\}_{m=1}^M,\left\{p_k\right\}_{k=1}^K} \left(\frac{[L^T(\mathbf{w}_{t_{p-1}})-L^T(\mathbf{w}_{t_p})]-[L^*(\mathbf{w}_{t_{p-1}})-L^*(\mathbf{w}_{t_p})]}{L^*(\mathbf{w}_{t_{p-1}})-L^*(\mathbf{w}_{t_p})}\right)^2$$
where $L^T$ is the training loss, and the generalization error $L^*$ measures how accurately the model can predict outcome values for previously unseen data. In general, $L^*$ is able to be computed by applying the model to the validation dataset. Adjacent global weights $\mathbf{w}_{t_{p-1}}$ and $\mathbf{w}_{t_{p}}$ are obtained by aggregating local updates from participanting clients. $t_{p}$ and $t_{p-1}$ denotes two adjacent communication rounds.
The obtained optimal modality weights $\left\{z_m\right\}_{m=1}^M$ and aggregation weights $\left\{p_k\right\}_{k=1}^K$ can reduce generalization errors while mitigating the divergence between local updates when training the global model. Our new mechanism does not introduce any trainable parameters, making it computationally friendly and easy to use. From a theoretical perspective, we show that HGB guarantees convergence in multi-modal FL with non-IID data.
We have evaluated the performance of our proposed HGB training algorithm in multi-modal FL using Plato, an open-source research framework to facilitate scalable federated learning research. Based on the Kinetics dataset that contains three modalities for action recognition tasks, we wish to evaluate the following:
-
whether the multi-modal global model trained by FedHGB can outperform its centrally trained uni-modal counterparts;
-
whether FedHGB is able to achieve higher performance than the state-of-the-art heterogeneous federated optimization method, FedNova, in terms of both accuracy and convergence speed.
After performing extensive experiments on 50 clients with multi-modal non-IID data, the accuracy of FedHGB is observed to be 2.06 higher than the centrally trained RGB models while achieving an improvement of 7.85 over the FedNova, with a reduction of communication rounds by at least 100. Our experimental results have demonstrated convincing evidence that FedHGB tends to assign higher weights to those clients with low generalization errors, making it a generalization-aware algorithm, which is consistent with our theoretical design.
Authored by Sijia Chen, this work has been published in the Proceedings of IEEE INFOCOM 2022.