Gradient Leakage in Production Federated Learning
As an emerging distributed machine learning paradigm, federated learning (FL) allows clients to train machine learning models collaboratively with private data, without transmitting them to the server. Though federated learning is celebrated as a privacy-preserving paradigm of training machine learning models, sharing gradients with the server may lead to the potential reconstruction of raw private data, such as images and texts, used in the training process. The discovery of this new attack, known as Deep Leakage from Gradients (DLG), has stimulated a new line of research to improve the attack efficiency and to provide stronger defenses against known DLG-family attacks as well.
As existing studies have made significant efforts to indicate that federated learning is vulnerable to gradient attacks from a malicious participant or eavesdropper, a lightweight defense that provides adequate privacy protection with guaranteed training accuracy is sought by recent work to prevent this attack. However, before designing for even more efficient and effective defense mechanisms, we begin to have second thoughts on how severe the threat is in practice, even without any defense mechanisms in place. Existing works focused on reconstructing raw data from known gradients or model weights in ideal settings, rather than considering practical settings in production federated learning.
Our original objective was to conduct an in-depth study of these attacks in the context of production federated learning systems, and to design a practical, simple, and lightweight defense mechanism that can be used to defend against real-world threats. Along our journey to achieve this goal, we discovered that the effectiveness and efficiency of existing gradient leakage attacks are weakened by a substantial margin in standard federated learning settings, where clients send model updates rather than gradients, perform multiple local training iterations over local data with a non-i.i.d. distribution, and initialize model weights normally.
As its name suggests, DLG proved that sharing gradients has the potential of leaking private data. However, when this attack was first proposed and later improved, most works in the literature considered sharing model updates as equivalent to sharing gradients. In production FL, however, multiple epochs are used routinely, and gradients are only accessible locally in a single step of gradient descent. No gradient — in its strict, original connotation — is transmitted to the server at all. Instead, only model updates — the delta between local models and the server’s global model in the preceding round — are transmitted from clients to the server. Yet, to the best of our knowledge, very little is known on the effectiveness of gradient attacks in practical contexts in production federated learning. It was shown that gradients can be calculated from model updates with a known learning rate; but with multiple epochs, we find that this calculation is far from accurate.
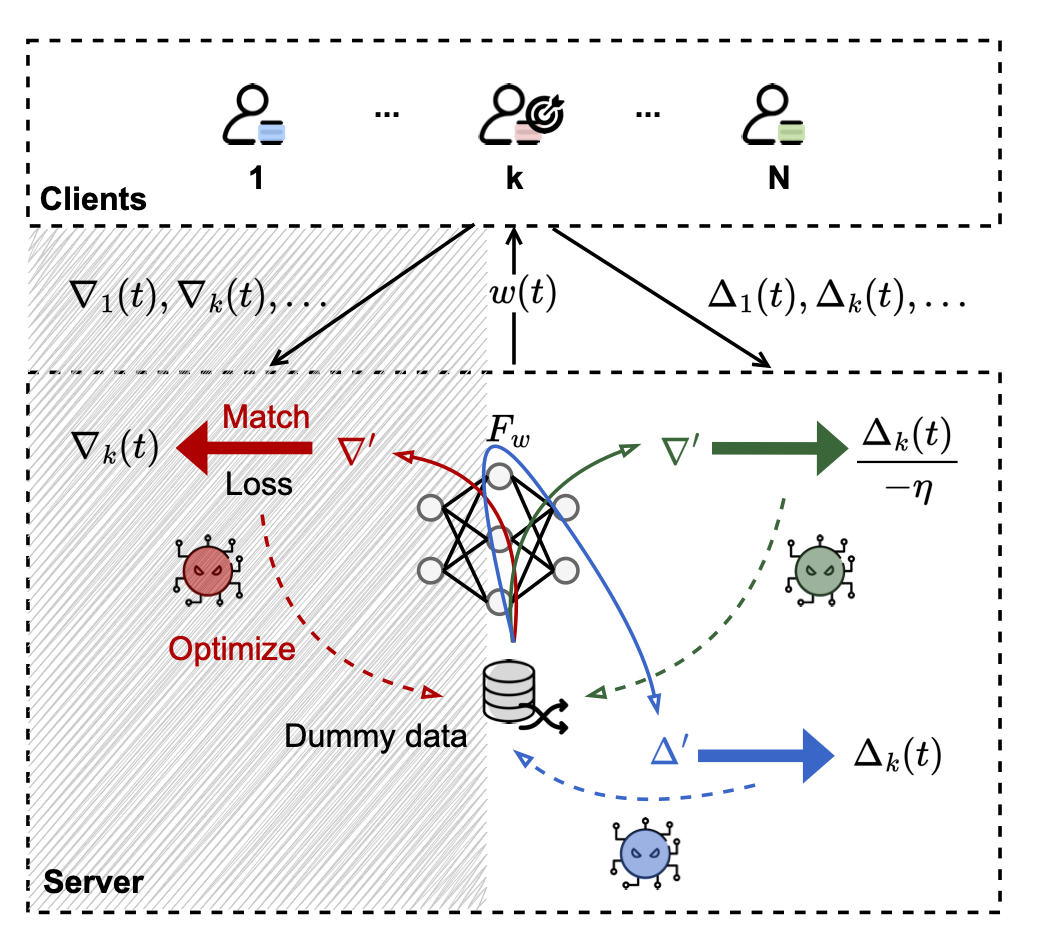
Figure: Three different ways of performing data reconstruction from deep leakage in federated learning: [Red] matching the dummy gradient with the target gradient; [Green] matching the dummy gradient with the approximated gradient converted from the model update; [Blue] matching the dummy model update with the model update directly. The shadow area indicates that matching dummy gradients directly from gradients is not possible in production FL, as local gradients will not be accessible by the server.
Even with the assumption of direct gradient sharing, existing works have mainly validated the efficiency when reconstructing one or multiple images (using a larger batch size) in full gradient descent, i.e., merely one local step of Stochastic Gradient Descent (SGD). None of them has shown convincing evidence that reconstructed images are recognizable by humans under the standard settings of production federated learning, where clients perform more local computation and less communication (i.e., multiple update steps on a local model). Moreover, existing attacks neglect the change of model status through FL training and tend to use untrained neural networks that are explicitly initialized with weights of a wide distribution for deriving gradients, which we have found makes the model and shared gradients fundamentally more vulnerable. Our empirical results disclose very limited privacy leakage even when gradients are shared, not to mention the privacy leakage with model updates, delta, only.

Figure: Reconstructing a single image using the DLG attack, with different model initialization methods or training stages.
Inspired by our empirical observations that models with weights from a narrower distribution and more local SGD update steps will effectively make potential attacks weaker, we propose a new defense mechanism, called Outpost, that provides sufficient and self-adaptive protection throughout the federated learning process against time-varying levels of privacy leakage risks. As its highlight, Outpost is designed to apply biased perturbation to gradients based on how spread out and how informative model weights are at different local update steps. Specifically, Outpost uses a probability threshold to decide whether we perform a perturbation to the gradients at the current step or not; and to limit the computation overhead, such a threshold decays as local update steps progress over time. When performing the perturbation, Outpost first evaluates privacy leakage risks of the current local model by the variance statistics of the model weights at each layer, and then adds Gaussian noise to each layer of the gradients of the current step based on the Fisher information matrix, whose range is decided by the quantified privacy leakage risks.
We have evaluated Outpost and four state-of-the-art defense mechanisms in the literature, against two gradient leakage attacks under both production FL settings and a simplistic, yet unrealistic, FL scenario where the attack is the most efficient. We seek to evaluate both utility metrics regarding both the wall-clock time needed to converge and the converged accuracy — and privacy metrics, which shows the effectiveness of the defenses against gradient leakage attacks in the worst case. With two image classification datasets and the same LeNet neural network architecture used in the literature, our experimental results have demonstrated convincing evidence that Outpost can achieve a much better accuracy compared with the state-of-the-art, incurs a much smaller amount of computational overhead, while effectively providing a sufficient level of protection against DLG attacks when evaluated using common privacy metrics in the literature.
Fei Wang is the first author of this work. It has been published in the Proceedings of IEEE INFOCOM 2023, and won the IEEE INFOCOM 2023 Best Paper Award.