Congestion Control with Deep Reinforcement Learning
For over a quarter of a century, it has been a fundamental challenge in networking research to design the best possible congestion control algorithms that optimize throughput and end-to-end latencies. Research interests in congestion control have recently been increasing as cloud applications have shown strong demands for higher throughput and lower latencies. Some prevailing congestion control algorithms may struggle to perform well on multiple diverse networks and/or to be fair towards other flows sharing the same network link.
To solve current issues in congestion control, we present Pareto, a congestion control algorithm fueled by deep reinforcement learning (DRL). Different from existing RL-based congestion control algorithms, Pareto uses expert demonstrations, a new staged training process, a multi-agent RL fairness training framework, and online adaptation to new environments. All of these techniques enable Pareto to perform well in a wide variety of environments in terms of high throughput, low latency, low loss rate and fairness to competing flows.
First, aiming to have Pareto behave fairly towards competing flows sharing the same link, we introduce a fairness training algorithm in the training process of Pareto. Our fairness training algorithm is a contribution to the field of reinforcement learning as it allows multiple agents to be deployed in a shared environment to achieve a common goal (fairness) without inter-agent communication.
Second, to avoid having fixed mappings between network events and congestion control responses, we introduce a new online training algorithm that allows Pareto to adapt to newly seen environments. This aims at generalizing the performance of Pareto to multiple network scenarios. While our algorithm improves the performance of Pareto on newly observed environments quickly, it also ensures that old experiences gained in offline learning are not forgotten.
Finally, to achieve generalization and a performant behavior in a wide variety of environments, Pareto is trained offline over a newly designed staged training algorithm, which involves three stages: (i) bootstrapping, (ii) advancing and (iii) fairness training. Each of these stages exposes the model to increasingly challenging sets of observations by encountering more challenging environments. All discussed training stages are summarized in the following figure.

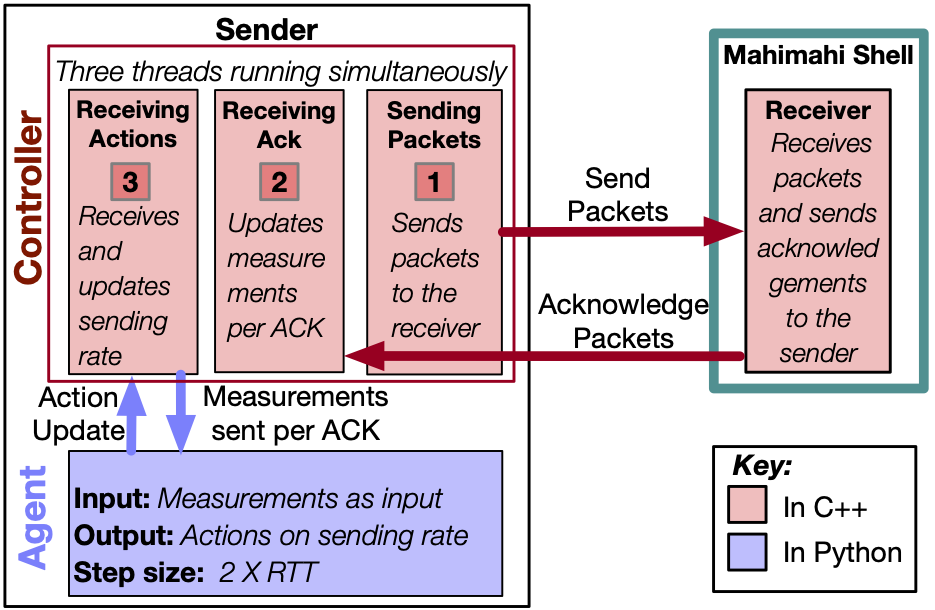
To train and test Pareto, we developed a reinforcement learning interface. The interface ensures the sender/s will continue sending packets until the agent takes a new decision to change the sending rate. This is feasible by running two different blocks/processes on the sender: the controller and agent. An outline of our interface is shown in the following figure.
During fairness training, Pareto learned to excel in shared networks. Pareto has up to 40% and 20% better fairness compared to state-of-the-art. The trade-off between throughput, latency and loss rate improved by 40% after online training in LTE networks. Overall, Pareto is capable of surpassing state-of-the-art congestion control algorithms by improving the trade-off between throughput, latency and loss rate, fairness towards flows sharing the same link, generalization and online adaptability.
Salma Emara is the first author of this work. It has been published in the IEEE Transactions on Network Science and Engineering TNSE 2022.